I'm working on a project that requires handwriting recognition (sending texts by writing them), and I've been exploring off-the-shelf options to recognize my own writing. Let's take a look at the contenders:
EasyORC
EasyOCR doesn't seem to be targeted at handwriting, so I wasn't expecting this to do particularly well. It does target reading images of text with 80+ languages.
simpleHTR
Harald Scheidl's PhD work implemented as a handwriting recognition system. I think the layout of my text might be difficult for simpleHTR to get; let's give it a shot though! For this I downloaded the line model (which should handle multiple lines of handwritten text) that was generated May 26 2021.
Tesseract
Some open source code, the original version of this library was developed at HP in the eighties and nineties, and open-sourced in 2005. Lead development was taken over by Google from then until 2018. Seems like it could be a great contender!
Google API
Ship it to Google and pay $1.50/1000 instead of using something free and open source. Of course, no github repo available.
Simple Test Results
Here's a script I wrote to compare and contrast these different systems:
from pdf2image import convert_from_path
import cv2
import numpy as np
import easyocr
import pytesseract
from autocorrect import Speller
from google.cloud import vision
#MUST 'brew install poppler'
#MUST 'brew install tesseract'
#to test simpleHTR, I created a PNG of the text
#and ran 'python main.py --img_file ../handwritingTestImage.png'
#in its src folder after importing the line model
#for google vision API, install google CLI using
#
#"curl https://sdk.cloud.google.com | bash"
#"gcloud init"
#"gcloud projects create dramsayocrtext" #this name must be unique to your project, of all projects ever created in gcloud
#"gcloud auth login"
#"gcloud config set project dramsayocrtext"
#"gcloud auth application-default login"
#"gcloud auth application-default set-quota-project dramsayocrtext"
#
#enable API in google cloud console
#enable billing in google cloud console ($1.50/1000 images)
#
#pip3 install google-cloud-vision
SHOW_IMAGES = False
SHARPEN = False
SPELLCHECK = False
OCR_ENGINE = 'GOOGLE' # 'GOOGLE', 'EASYOCR', 'TESSERACT'
def show(img):
cv2.imshow("img", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# grab handwriting pdf with convert_from_path function
images = convert_from_path('8234567890.pdf', poppler_path="/usr/local/Cellar/poppler/23.03.0/bin")
img = np.array(images[0])
# Crop to just the part with the handwriting
img = img[2*395:2*1170,0:2*827]
# Greyscale and Sharpen
if SHARPEN:
print('using greyscale and threshold to sharpen.')
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
if SHOW_IMAGES: show(img)
sharpen_kernel = np.array([[-1,-1,-1], [-1,9,-1], [-1,-1,-1]])
img = cv2.filter2D(img, -1, sharpen_kernel)
img = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
if SHOW_IMAGES: show(img)
# OCR
if OCR_ENGINE=='EASYOCR':
print('using easyocr.')
reader = easyocr.Reader(['en'],gpu = False)
ocr_output = reader.readtext(img,paragraph=True)[0][1]
elif OCR_ENGINE=='TESSERACT':
print('using tesseract.')
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
ocr_output = pytesseract.image_to_string(img_rgb)
elif OCR_ENGINE=='GOOGLE':
print('using google cloud.')
success, img_jpg = cv2.imencode('.jpg', img)
byte_img = img_jpg.tobytes()
google_img = vision.Image(content=byte_img)
client = vision.ImageAnnotatorClient()
resp = client.text_detection(image=google_img)
ocr_output = resp.text_annotations[0].description.replace('\n',' ')
else:
ocr_output = ' ERROR: no ocr tool selected. Choose "GOOGLE","EASYOCR", or "TESSERACT"'
# Spellcheck
if SPELLCHECK:
print('using autocorrect.')
spell = Speller(only_replacements=True)
final_text = spell(ocr_output)
ocr_output += ' (OCRed in python; forgive typos)'
print('-'*10)
print(ocr_output)
print('-'*10)
We're going 80/20 here, and I only actually care about how well these work on my handwriting. This is my initial test image, which I wrote on a ReMarkable tablet, filled with the kinds of phrases I might actually use:

Results
EasyOCR: "wnrivg 0 les+ Ths 1S Mq bec o Sme 6nQ . T MasSas? anj keb Iove miss Yu X , Wea} (c {C9 Crean ak US Toscnims . Sea 4PM 0t YX Hen ' _Davi&"
EasyOCR+Sharpen: "waring a Jez+ Ths 1S MQ Becl to Sme &n9 1 MSSGS anj leb Iove YbU Wiss Xu , wes F Cac iC Cream at US Toscanims Sea 4pM at Y Hlen ' ~Davia"
Tesseract: "Tw aces iS we paring a texX snipe DAS ie Ss On. - Lob 0, {ove LEPM od Cor ice Cream ok Tos canims ae . ye Hye! ai =David ©"
Tesseract+Sharpen: "Thm eae iS Wwe wary a ie cong Bee te & : weons. L Lob 0 , {ove LEPM od Gor ice Cream ok Tos canims ee i Hye! ai =David ©"
simpleHTR: "c"
simpleHTR doesn't seem to handle this multi-line image well. Just to see what would happen if I added a simple pre-processing step to do individual lines of text, I also tried simpleHTR with this image:
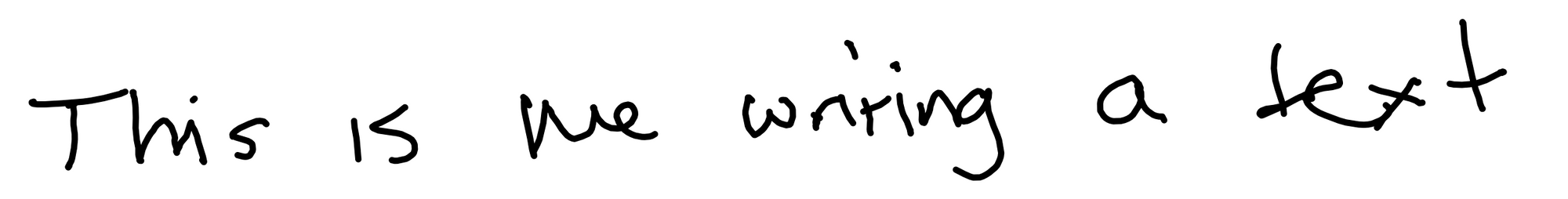
simpleHTR: "This 1s e wniving Sert"
None of the local options work well enough. Luckily, we can just use Google's actual API.
Google Vision API: "me writing a text back to someone. I let This is message love you and miss you. us weet for ice cream at 4PM at Toscaninis. See you then! -David"

It gets the words (mostly), but the line sensitivity is really high. This happens with both text_detection and document_text_detection.
Final Solution
We have two options: help the OCR algorithm or do the line segmentation ourselves. Since google reports the coordinates of each word, it actually wouldn't be too hard to do the line segmentation ourselves (since we know a priori roughly how large my handwriting tends to be). It would be nice to give the algorithm a hint about minimum line height, but that isn't currently supported. In the name of speed, let's simply try to add lines to give the OCR algorithm a hint:

Google Vision API: "This is me writing a text message back to someone. I love you and miss Let you. us weet for ice cream at 4PM at Toscaninis. See you then! -David ☺:)"
It does seem to help; we have one out of place word (Let) and one wrong word (weet). Passing this through the autocorrect actually made it worse ('weet' to 'went' instead of 'meet'). It also reveals how naturally slanty my writing can be without lines to write on. For now, I'm going to simply give myself some lines in my PDF template and we'll see how well it works!
